
After you develop the logical model of the new system, you may use it to create a physical data flow diagram. The physical data flow diagram shows how the system will be constructed, and usually contains most, if not all, of the elements found in the table illustrated below. Just as logical data flow diagrams have certain advantages, physical data flow diagrams have others, including:
- Clarifying which processes are performed by humans (manual) and which are automated.
- Describing processes in more detail than logical DFDs.
- Sequencing processes that have to be done in a particular order.
- Identifying temporary data stores.
- Specifying actual names of files, database tables, and printouts.
- Adding controls to ensure the processes are done properly.
| Contents of Physical Data Flow Diagrams |
|---|
|
Physical data flow diagrams contain many items not found in logical data flow diagrams.
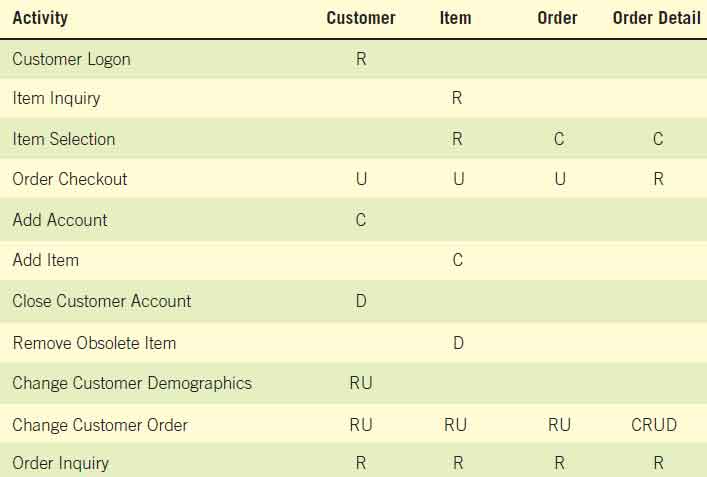
Physical data flow diagrams are often more complex than logical data flow diagrams simply because of the many data stores present in a system. The acronym CRUD is often used for Create, Read, Update, and Delete, the activities that must be present in a system for each master file. A CRUD matrix is a tool to represent where each of these processes occurs in a system. Figure 1 is a CRUD matrix for an Internet storefront. Notice that some of the processes include more than one activity. Data entry processes such as keying and verifying are also part of physical data flow diagrams.
Physical data flow diagrams also have intermediate data stores, often a transaction file or a temporary database table. Intermediate data stores often consist of transaction files used to store data between processes. Because most processes that require access to a given set of data are unlikely to execute at the same instant in time, transaction files must hold the data from one process to the next. An easily understood example of this concept is found in the everyday experiences of grocery shopping, meal preparation, and eating. The activities are:
- Selecting items from shelves.
- Checking out and paying the bill.
- Transporting the groceries home.
- Preparing a meal.
- Eating the meal.
Each of these five activities would be represented by a separate process on a physical data flow diagram, and each one occurs at a different time. For example, you would not typically transport the groceries home and eat them at the same time. Therefore, a “transaction data store” is required to link each task. When you are selecting items, the transaction data store is the shopping cart. After the next process (checking out), the cart is unnecessary. The transaction data store linking checking out and transporting the groceries home is the shopping bag (cheaper than letting you take the cart home!). Bags are an inefficient way of storing the groceries once they are home, so cupboards and a refrigerator are used as a transaction data store between the activity of transporting the goods home and preparing the meal. Finally, a plate, bowl, and cup constitute the link between preparing and eating the meal.
Timing information may also be included. For example, a physical DFD may indicate that an edit program must be run before an update program. Updates must be performed before producing a summary report, or an order must be entered on a Web site before the amount charged to a credit card may be verified with the financial institution. Note that because of such considerations, a physical data flow diagram may appear more linear than a logical model.
Create the physical data flow diagram for a system by analyzing its output and input. When creating a physical data flow diagram, input data flow from an external entity is sometimes called a trigger because it starts the activities of a process, and output data flow to an external entity is sometimes called a response because it is sent as the result of some activity. Determine which data fields or elements need to be keyed. These fields are called base elements and must be stored in a file. Elements that are not keyed but are rather the result of a calculation or logical operation are called derived elements.
Sometimes it is not clear how many processes to place in one diagram and when to create a child diagram. One suggestion is to examine each process and count the number of data flows entering and leaving it. If the total is greater than four, the process is a good candidate for a child diagram. Physical data flow diagrams are illustrated later in this chapter.
Event Modeling and Data Flow Diagrams
A practical approach to creating physical data flow diagrams is to create a simple data flow diagram fragment for each unique system event. Events cause the system to do something and act as a trigger to the system. Triggers start activities and processes, which in turn use data or produce output. An example of an event is a customer reserving a flight on the Web. As each Web form is submitted, processes are activated, such as validating and storing the data and formatting and displaying the next Web page.
Events are usually summarized in an event response table. An example of an event response table for an Internet storefront business is illustrated in Figure 2. A data flow diagram fragment is represented by a row in the table. Each DFD fragment is a single process on a data flow diagram. All the fragments are then combined to form Diagram 0. The trigger and response columns become the input and output data flows, and the activity becomes the process. The analyst must determine the data stores required for the process by examining the input and output data flows. Figure 3 illustrates a portion of the data flow diagram for the first three rows of the event response table.
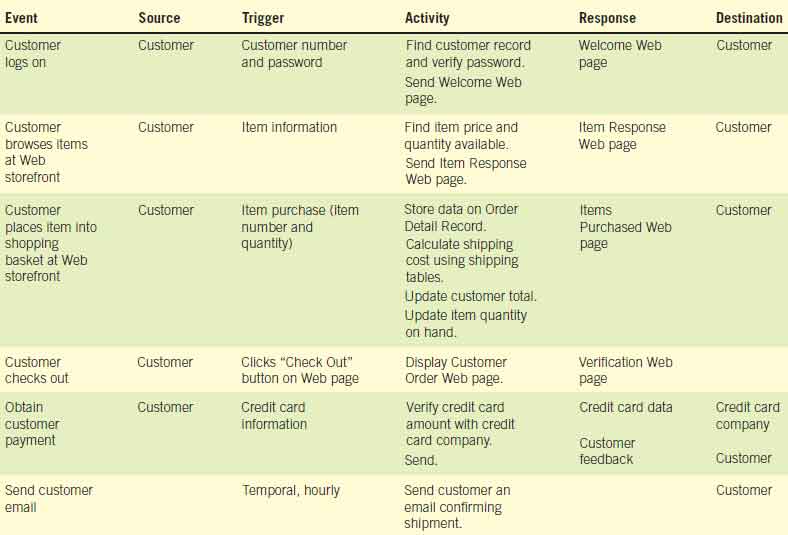
The advantage of building data flow diagrams based on events is that the users are familiar with the events that take place in their business area and know how the events drive other activities.
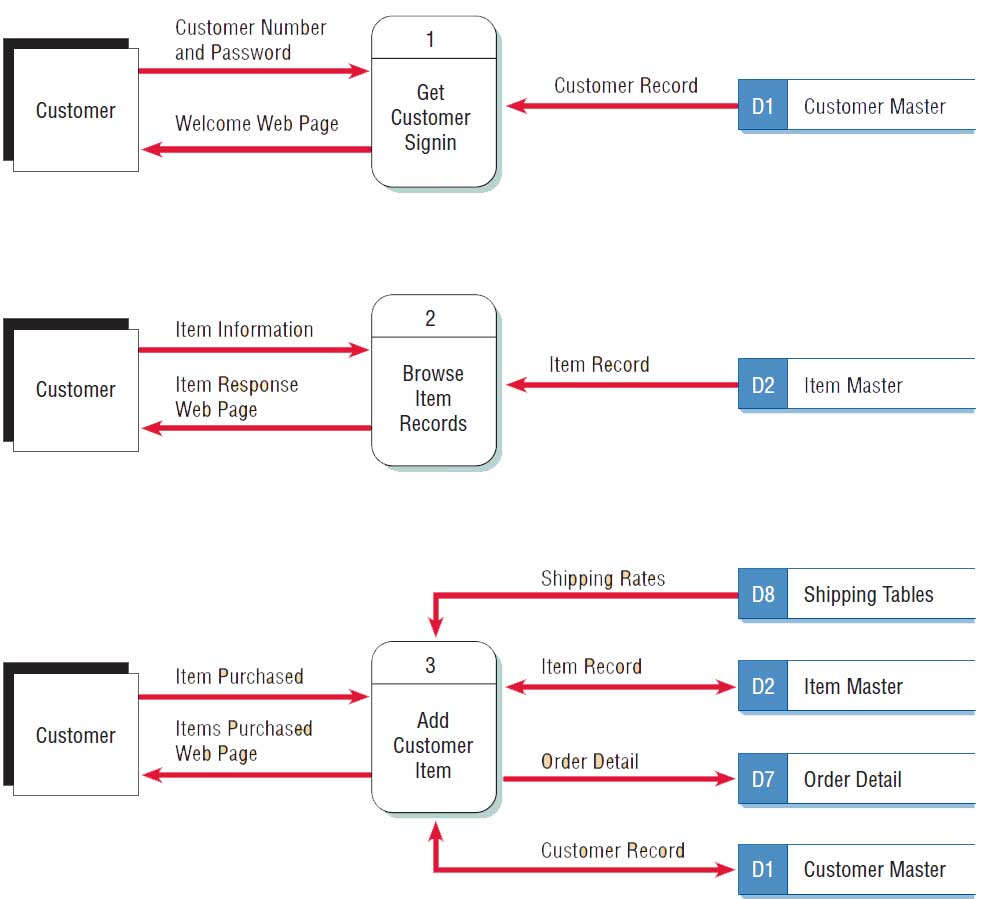
Use Cases and Data Flow Diagrams
In Chapter “Understanding and Modeling Organizational Systems“, we introduced the concept of a use case. We use this notion of a use case in creating data flow diagrams. A use case summarizes an event and has a similar format to process specifications (described in Chapter 9). Each use case defines one activity and its trigger, input, and output. Figure 4 illustrates a use case for Process 3, Add Customer Item.
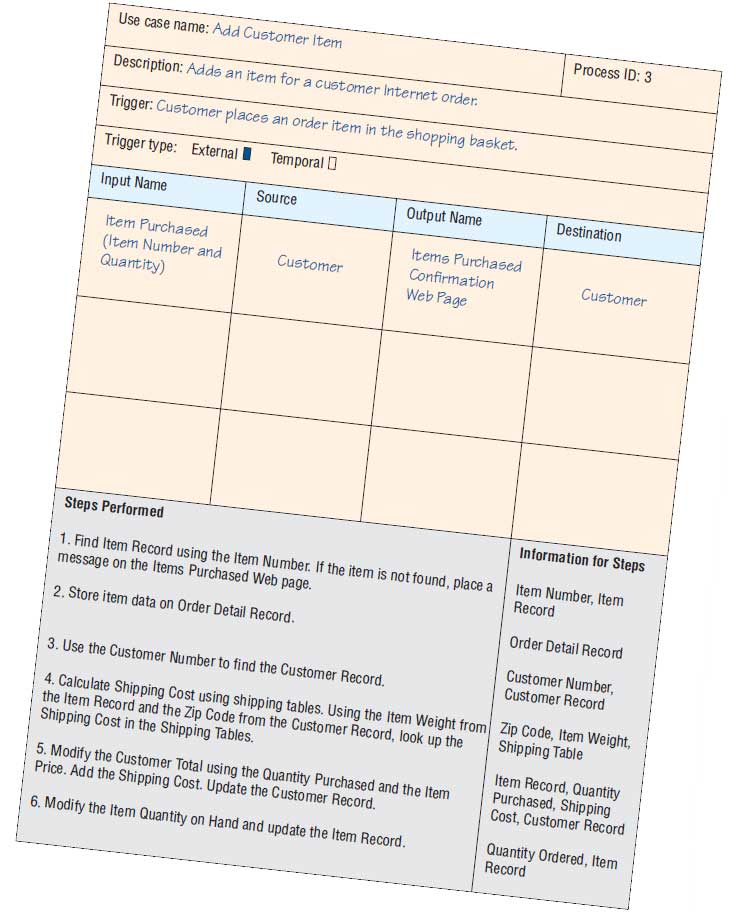
This approach allows the analyst to work with users to understand the nature of the processes and activities and then create a single data flow diagram fragment. When creating use cases, first make an initial attempt to define the use cases without going into detail. This step provides an overview of the system and leads to the creation of Diagram 0. Decide what the names should be and provide a brief description of the activity. List the activities, inputs, and outputs for each one.
Make sure you document the steps used in each use case. These should be in the form of business rules that list or explain the human and system activities completed for each use case. If at all possible, list them in the sequence that they would normally be executed. Next, determine the data used by each step. This step is easier if a data dictionary has been completed. Finally, ask the users to review and suggest modifications of the use cases. It is important that the use cases are written clearly. (See Chapter 10 for a further discussion of UML, use cases, and use case diagrams.)