
Data warehouses differ from traditional databases. The purpose of a data warehouse is to organize information for quick and effective queries. In effect, they store denormalized data, but they go one step further. They organize data around subjects. Most often, a data warehouse is more than one database processed so that data are represented in uniform ways. Therefore, the data stored in data warehouses comes from different sources, usually databases that were set up for different purposes. The data warehouse concept is unique. Differences between data warehouses and traditional databases include the following:
- In a data warehouse, data are organized around major subjects rather than individual transactions.
- Data in a data warehouse are typically stored as summarized data rather than the detailed, raw data found in a transaction-oriented database.
- Data in a data warehouse cover a much longer time frame than data in traditional transaction-oriented databases because queries usually concern longer-term decision making rather than daily transaction details.
- Most data warehouses are organized for fast queries, whereas the more traditional databases are normalized and structured in such a way as to provide efficient storage of information.
- Data warehouses are usually optimized for answering complex queries, known as OLAP, from managers and analysts, rather than simple, repeatedly asked queries.
- Data warehouses allow easy access via data mining software (called siftware) that searches for patterns and is able to identify relationships not imagined by human decision makers.
- Data warehouses include not just one but multiple databases that have been processed so that the warehouse’s data are defined uniformly. These databases are referred to as clean data.
- Data warehouses usually include data from outside sources (such as an industry report, the company’s Security and Exchange Commission filing, or even information about competitors’ products), as well as data generated for internal use.
Building a data warehouse is a monumental task. The analyst needs to gather data from a variety of sources and translate that data into a common form. For example, one database may store information about gender as “Male” and “Female,” another may store it as “M” and “F,” and a third may store it as “1” and “0.” The analyst needs to set a standard and convert all the data to the same format.
Once the data are clean, the analyst has to decide how to summarize the data. Once summarized, the detail is lost, so an analyst has to predict the type of queries that might be asked. Then, the analyst needs to design the data warehouse by logically organizing, and perhaps even physically clustering, the data by subject, requiring much analysis and design. The analyst needs to know a substantial amount about the business.
Typical data warehouses tend to be from 50 gigabytes to tens of terabytes in size. Because they are large, they are also expensive. Most data warehouses cost millions of dollars.
Online Analytic Processing
First introduced in 1993 by E. F. Codd, online analytic processing (OLAP) was meant to answer decision makers’ complex questions. Codd concluded that a decision maker had to look at data in a number of different ways. Therefore, the database itself had to be multidimensional. Many people picture OLAP as a Rubik’s Cube of data. You can look at the data from all different sides, and can also manipulate the data by twisting or turning it so that it makes sense.
This OLAP approach validated the concept of data warehouses. It then made sense for data to be organized in ways that allowed efficient queries. Of course,OLAP involves the processing of data through manipulation, summarization, and calculation, so more than a data warehouse is involved.
Data Mining
Data mining can identify patterns that a human is unable to detect. Either the decision maker cannot see a pattern, or perhaps the decision maker is not able to think about asking whether that pattern exists. Data mining algorithms search data warehouses for patterns using algorithms. Figure 13.27 illustrates the concept of data mining.
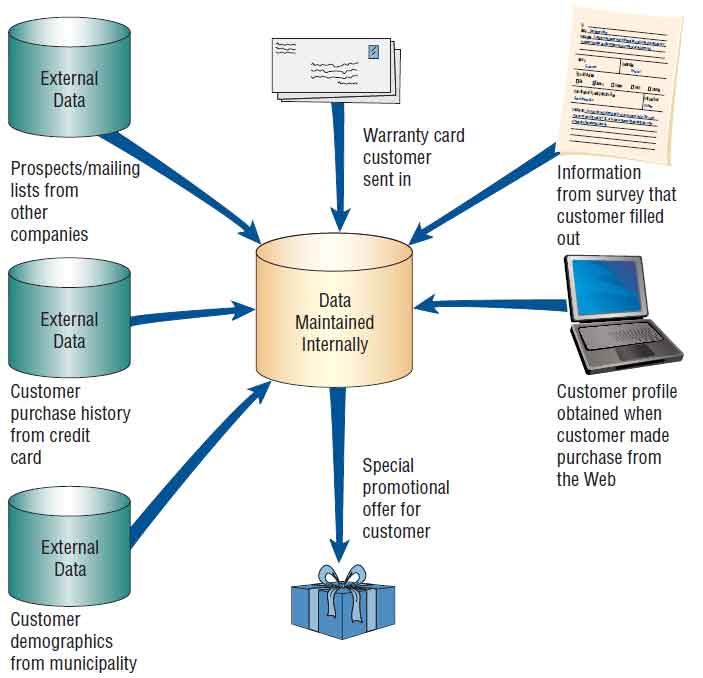
Data mining is known by another name, knowledge data discovery (KDD). Some think that KDD differs from data mining because KDD is meant to assist decision makers in finding patterns rather than turning control over to an algorithm to find them. The decision aids available are called siftware; they include statistical analysis, decision trees, neural networks, intelligent agents, fuzzy logic, and data visualization.
The types of patterns decision makers try to identify include associations, sequences, clustering, and trends. Associations are patterns that occur together at the same time. For example, a person who buys cereal usually buys milk to go with the cereal. Sequences, on the other hand, are patterns of actions that take place over a period of time. For example, if a family buys a house this year, they will most likely buy durables (a refrigerator, or washer and dryer) next year. Clustering is the pattern that develops among a group of people. For example, customers who live in a particular zip code may tend to buy a particular car. Finally, trends are patterns that are noticed over a period of time. For example, consumers may move from buying generic goods to premium products.
The concept of data mining came from the desire to use a database for a more selective targeting of customers. Early approaches to direct mail included using zip code information as a way to determine what a family’s income might be (assuming a family must generate sufficient income to afford to live in the prestigious Beverly Hills zip code 90210 or some other affluent neighborhood). It was a way (not perfect, of course) to limit the number of catalogs sent.
Data mining takes this concept one step further. Assuming past behavior is a good predictor for future purchases, a large amount of data is gathered on a particular person from credit card purchases. The company can identify what stores we shop in, what we have purchased, how much we paid for an item, and when and how frequently we travel. Data are also entered, stored, and used for a variety of purposes when we fill out warranties, apply for a driver’s license, respond to a free offer, or apply for a membership card at a video rental store. Moreover, companies share these data and often make money on the sale of them as well.
American Express has been a leader in data mining for marketing purposes. American Express will send you discount coupons for new stores or entertainment when it sends you a credit card bill, having determined that you have shopped in similar stores or attended similar events. General Motors offers a MasterCard that allows customers to accumulate bonus points toward the purchase of a new car, and then sends out information about new vehicles at the most likely time that a consumer would be interested in purchasing a new car.
The data mining approach is not without problems, however. First, the costs may be too high to justify data mining, something that may only be discovered after huge setup costs have been accrued. Second, data mining has to be coordinated so that various departments or subsidiaries do not all try to reach the customer at the same time. In addition, customers may think their privacy has been invaded and resent the offers that are coming their way. Finally, customers may think profiles created solely on the basis of their credit card purchases present a highly distorted image of who they are.
Analysts should take responsibility for considering the ethical aspects of any data mining projects that are proposed. Questions about the length of time profile material is kept, the confidentiality of it, the privacy safeguards included, and the uses to which inferences are put should all be asked and considered with the client. The opportunities for abuse are apparent and must be guarded against. For consumers, data mining is another push technology, and if consumers do not want to be pushed, the data mining efforts will backfire.