

Concurrency can lead to several negative effects, such as the reading of nonexistent data or loss of modified data. Consider this real-world example illustrating one of these negative effects, called dirty read: User U1 in the personnel department gets notice of an address change for the employee Jim Smith. U1 makes the address change, but when viewing the bank account information of Mr. Smith in the consecutive dialog step, he realizes that he modified the address of the wrong person. (The enterprise employs two persons with the name Jim Smith.) Fortunately, the application allows the user to cancel this change by clicking a button. U1 clicks the button, knowing that he has committed no error.
At the same time, user U2 in the technical department retrieves the data of the latter Mr. Smith to send the newest technical document to his home, because the employee seldom comes to the office. As the employee’s address was wrongly changed just before U2 retrieved the address, U2 prints out the wrong address label and sends the document to the wrong person.
To prevent problems like these in the pessimistic concurrency model, every DBMS must have mechanisms that control the access of data by all users at the same time. The Database Engine, like all relational DBMSs, uses locks to guarantee the consistency of the database in case of multiuser access. Each application program locks the data it needs, guaranteeing that no other program can modify the same data. When another application program requests the modification of the locked data, the system either stops the program with an error or makes a program wait.
Locking has several different aspects:
- Lock duration
- Lock modes
- Lock granularity
Lock duration specifies a time period during which a resource holds the particular lock. Duration of a lock depends on, among other things, the mode of the lock and the choice of the isolation level.
The next two sections describe lock modes and lock granularity.
Note – The following discussion concerns the pessimistic concurrency model. The optimistic concurrency model is
handled using row versioning, and will be explained at the end of this chapter.
Lock Modes
Lock modes specify different kinds of locks. The choice of which lock mode to apply depends on the resource that needs to be locked. The following three lock types are used for row- and page-level locking:
- Shared (S)
- Exclusive (X)
- Update (U)
A shared lock reserves a resource (page or row) for reading only. Other processes cannot modify the locked resource while the lock remains. On the other hand, several processes can hold a shared lock for a resource at the same time—that is, several processes can read the resource locked with the shared lock.
An exclusive lock reserves a page or row for the exclusive use of a single transaction. It is used for DML statements (INSERT, UPDATE, and DELETE) that modify the resource. An exclusive lock cannot be set if some other process holds a shared or exclusive lock on the resource—that is, there can be only one exclusive lock for a resource. Once an exclusive lock is set for the page (or row), no other lock can be placed on the same resource.
An update lock can be placed only if no other update or exclusive lock exists. On the other hand, it can be placed on objects that already have shared locks. (In this case, the update lock acquires another shared lock on the same object.) If a transaction that modifies the object is committed, the update lock is changed to an exclusive lock if there are no other locks on the object. There can be only one update lock for an object.
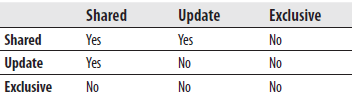
Table 13-1 shows the compatibility matrix for shared, exclusive, and update locks. The matrix is interpreted as follows: suppose transaction T1 holds a lock as specified in the first column of the matrix, and suppose some other transaction, T2, requests a lock as specified in the corresponding column heading. In this case, “yes” indicates that a lock of T2 is possible, whereas “no” indicates a conflict with the existing lock.
Table 13-1 Compatibility Matrix for Shared, Exclusive, and Update Locks
At the table level, there are five different types of locks:
- Shared (S)
- Exclusive (X)
- Intent shared (IS)
- Intent exclusive (IX)
- Shared with intent exclusive (SIX)
Shared and exclusive locks correspond to the row-level (or page-level) locks with the same names. Generally, an intent lock shows an intention to lock the next-lower resource in the hierarchy of the database objects. Therefore, intent locks are placed at a level in the object hierarchy above that which the process intends to lock. This is an efficient way to tell whether such locks will be possible, and it prevents other processes from locking the higher level before the desired locks can be attained.
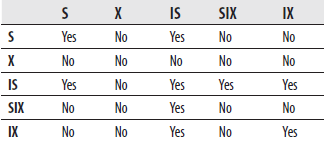
Table 13-2 shows the compatibility matrix for all kinds of table locks. The matrix is interpreted exactly as the matrix in Table 13-1.
Table 13-2 Compatibility Matrix for All Kinds of Table Locks
Lock Granularity
Lock granularity specifies which resource is locked by a single lock attempt. The Database Engine can lock the following resources:
- Row
- Page
- Index key or range of index keys
- Table
- Extent
- Database itself
A row is the smallest resource that can be locked. The support of row-level locking includes both data rows and index entries. Row-level locking means that only the row that is accessed by an application will be locked. Hence, all other rows that belong to the same page are free and can be used by other applications. The Database Engine can also lock the page on which the row that has to be locked is stored.
Locking is also done on disk units, called extents, that are 64K in size (see Chapter “System Environment
of the Database Engine”). Extent locks are set automatically when a table (or index) grows and the additional disk space is needed.
Lock granularity affects concurrency. In general, the more granular the lock, the more concurrency is reduced. This means that row-level locking maximizes concurrency because it leaves all but one row on the page unlocked. On the other hand, system overhead is increased because each locked row requires one lock. Page-level locking (and table-level locking) restricts the availability of data but decreases the system overhead.
Lock Escalation
If many locks of the same granularity are held during a transaction, the Database Engine automatically upgrades these locks into a table lock. This process of converting many page-, row-, or index-level locks into one table lock is called lock escalation. The escalation threshold is the boundary at which the database system applies the lock escalation. Escalation thresholds are determined dynamically by the system and require no configuration. (Currently, the threshold boundary is 5000 locks.)
The general problem with lock escalation is that the database server decides when to escalate a particular lock, and this decision might be suboptimal for applications with different requirements. You can use the ALTER TABLE statement to change the lock escalation mechanism. This statement supports the TABLE option with the following syntax:
SET ( LOCK_ESCALATION = { TABLE | AUTO | DISABLE } )The TABLE option is the default value and specifies that lock escalation will be done at table-level granularity. The AUTO option allows the Database Engine to select the lock escalation granularity that is appropriate for the table schema. Finally, the DISABLE option allows you to disable lock escalation in most cases. (There are some cases in which the Database Engine must take a table lock to protect data integrity.)
Example 13.3 disables the lock escalation for the employee table.
USE sample;
ALTER TABLE employee SET (LOCK_ESCALATION = DISABLE);Code language: PHP (php)