

Designing a database is a very important phase in the database life cycle, which precedes all other phases except the requirements collection and the analysis. If the database design is created merely intuitively and without any plan, the resulting database will most likely not meet the user requirements concerning performance.
Another consequence of a bad database design is superfluous data redundancy, which in itself has two disadvantages: the existence of data anomalies and the use of an unnecessary amount of disk space.
Normalization of data is a process during which the existing tables of a database are tested to find certain dependencies between the columns of a table. If such dependencies exist, the table is restructured into multiple (usually two) tables, which eliminates any column dependencies. If one of these generated tables still contains data dependencies, the process of normalization must be repeated until all dependencies are resolved.
The process of eliminating data redundancy in a table is based upon the theory of functional dependencies. A functional dependency means that by using the known value of one column, the corresponding value of another column can always be uniquely determined. (The same is true for column groups.) The functional dependencies between columns A and B is denoted by A ⇒ B, specifying that a value of column A can always be used to determine the corresponding value of column B. (“B is functionally dependent on A.”)
Example 1.1 shows the functional dependency between two attributes of the table employee in the sample database.
emp_no ⇒ emp_lname
By having a unique value for the employee number, the corresponding last name of the employee (and all other corresponding attributes) can be determined. This kind of functional dependency, where a column is dependent upon the primary key of a table, is called trivial functional dependency.
Another kind of functional dependency is called multivalued dependency. In contrast to the functional dependency just described, the multivalued dependency is specified for multivalued attributes. This means that by using the known value of one attribute (column), the corresponding set of values of another multivalued attribute can be uniquely determined. The multivalued dependency is denoted by ⇒ ⇒.
Example 1.2 shows the multivalued dependency that holds for two attributes of the object BOOK.
ISBN ⇒ ⇒ Authors
The ISBN of a book always determines all of its authors. Therefore, the Authors attribute is multivalued dependent on the ISBN attribute.
Normal Forms
Normal forms are used for the process of normalization of data and therefore for the database design. In theory, there are at least five different normal forms, of which the first three are the most important for practical use. The third normal form for a table can be achieved by testing the first and second normal forms at the intermediate states, and as such, the goal of good database design can usually be fulfilled if all tables of a database are in the third normal form.
First Normal Form
First normal form (1NF) means that a table has no multivalued attributes or composite attributes. (A composite attribute contains other attributes and can therefore be divided into smaller parts.) All relational tables are by definition in 1NF, because the value of any column in a row must be atomic—that is, single valued.
Table 1-5 demonstrates 1NF using part of the works_on table from the sample database. The rows of the works_on table could be grouped together, using the employee number. The resulting Table 1-6 is not in 1NF because the column project_no contains a set of values (p1, p3).
Table 1-5 Part of the works_on Table
| emp_no | project_no | ................. |
|---|---|---|
| 10102 | p1 | ................. |
| 10102 | p3 | ................. |
| ................. | ................. | ................. |
Table 1-6 This “Table” Is Not in 1NF
| emp_no | project_no | ................. |
|---|---|---|
| 10102 | (p1, p3) | ................. |
| ................. | ................. | ................. |
Second Normal Form
A table is in second normal form (2NF) if it is in 1NF and there is no nonkey column dependent on a partial primary key of that table. This means if (A,B) is a combination of two table columns building the key, then there is no column of the table depending either on only A or only B.
For example, Table 1-7 shows the works_on1 table, which is identical to the works_on table except for the additional column, dept_no. The primary key of this table is the combination of columns emp_no and project_no. The column dept_no is dependent on the partial key emp_no (and is independent of project_no), so this table is not in 2NF. (The original table, works_on, is in 2NF.)
Table 1-7 The works_on1 Table
| emp_no | project_no | job | enter_date | dept_no |
|---|---|---|---|---|
| 10102 | p1 | Analyst | 2006.10.1 | d3 |
| 10102 | p3 | Manager | 2008.1.1 | d3 |
| 25348 | p2 | Clerk | 2007.2.15 | d3 |
| 18316 | p2 | NULL | 2007.6.1 | d1 |
| ............... | ............... | ............... | ............... |
Third Normal Form
A table is in third normal form (3NF) if it is in 2NF and there are no functional dependencies between nonkey columns. For example, the employee1 table (see Table 1-8), which is identical to the employee table except for the additional column, dept_name, is not in 3NF, because for every known value of the column dept_no the corresponding value of the column dept_name can be uniquely determined. (The original table, employee, as well as all other tables of the sample database are in 3NF.)
Table 1-8 The employee1 Table
| emp_no | emp_fname | emp_lname | dept_no | dept_name |
|---|---|---|---|---|
| 25348 | Matthew | Smith | d3 | Marketing |
| 10102 | Ann | Jones | d3 | Marketing |
| 18316 | John | Barrimore | d1 | Research |
| 29346 | James | James | d2 | Accounting |
| ............... | ............... | ............... | ............... | ............... |
Entity-Relationship Model
The data in a database could easily be designed using only one table that contains all data. The main disadvantage of such a database design is its high redundancy of data. For example, if your database contains data concerning employees and their projects (assuming each employee works at the same time on one or more projects, and each project engages one or more employees), the data stored in a single table contains many columns and rows. The main disadvantage of such a table is that data is difficult to keep consistent because of its redundancy.
The entity-relationship (ER) model is used to design relational databases by removing all existing redundancy in the data. The basic object of the ER model is an entity—that is, a real-world object. Each entity has several attributes, which are properties of the entity and therefore describe it. Based on its type, an attribute can be
- Atomic (or single valued) – An atomic attribute is always represented by a single value for a particular entity. For example, a person’s marital status is always an atomic attribute. Most attributes are atomic attributes.
- Multivalued – A multivalued attribute may have one or more values for a particular entity. For example, Location as the attribute of an entity called ENTERPRISE is multivalued, because each enterprise can have one or more locations.
- Composite – Composite attributes are not atomic because they are assembled using some other atomic attributes. A typical example of a composite attribute is a person’s address, which is composed of atomic attributes, such as City, Zip, and Street.
The entity PERSON in Example 1.3 has several atomic attributes, one composite attribute, Address, and a multivalued attribute, College_degree.
Example 1.3
PERSON (Personal_no, F_name, L_name, Address(City,Zip,Street),{College_degree})
Each entity has one or more key attributes that are attributes (or a combination of two or more attributes) whose values are unique for each particular entity. In Example 1.3, the attribute Personal_no is the key attribute of the entity PERSON.
Besides entity and attribute, relationship is another basic concept of the ER model. A relationship exists when an entity refers to one (or more) other entities. The number of participating entities defines the degree of a relationship. For example, the relationship works_on between entities EMPLOYEE and PROJECT has degree two.
Every existing relationship between two entities must be one of the following three types: 1:1, 1:N, or M:N. (This property of a relationship is also called cardinality ratio.) For example, the relationship between the entities DEPARTMENT and EMPLOYEE is 1:N, because each employee belongs to exactly one department, which itself has one or more employees. Also, the relationship between the entities PROJECT and EMPLOYEE is M:N, because each project engages one or more employees and each employee works at the same time on one or more projects.
A relationship can also have its own attributes. Figure 1-1 shows an example of an ER diagram. (The ER diagram is the graphical notation used to describe the ER model.)
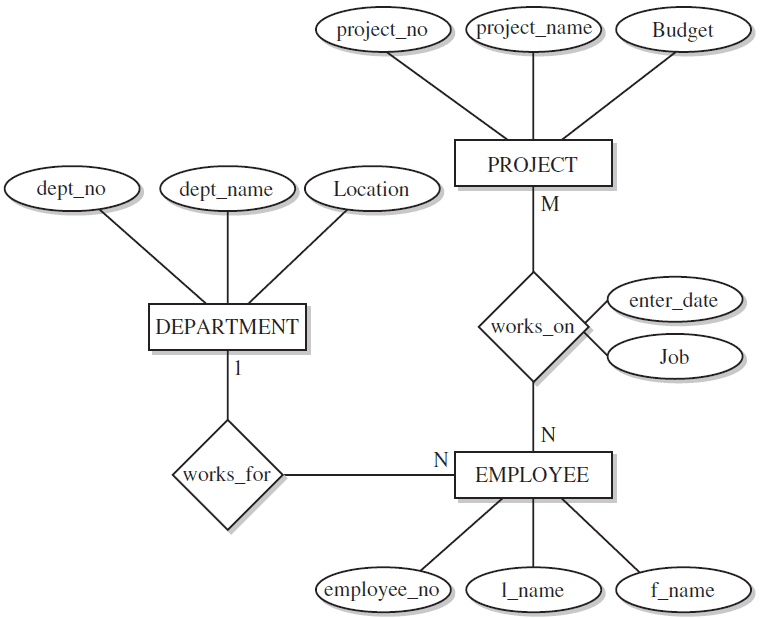
Using this notation, entities are modeled using rectangular boxes, with the entity name written inside the box. Attributes are shown in ovals, and each attribute is attached to a particular entity (or relationship) using a straight line. Finally, relationships are modeled using diamonds, and entities participating in the relationship are attached to it using straight lines. The cardinality ratio of each entity is written on the corresponding line.
Syntax Conventions
This book uses the conventions shown in Table 1-9 for the syntax of the Transact-SQL statements and for the indication of the text.
| Convention | Indication |
|---|---|
| Italics | New terms or items of emphasis. |
| UPPERCASE | Transact-SQL keywords—for example, CREATE TABLE. |
| lowercase | Variables in Transact-SQL statements—for example, CREATE TABLE tablename. (The user must replace "tablename" with the actual name of the table.) |
| var1 | var2 | Alternative use of the items var1 and var2. (You may choose only one of the items separated by the vertical bar.) |
| { } | Alternative use of more items. Example: { expression | USER | NULL } |
| [ ] | Optional item(s). Example: [FOR LOAD] |
| { } ... | Item(s) that can be repeated any number of times. Example: {, @param1 typ1} … |
| bold | Name of database object (database itself, tables, columns) in the text. |
| Default | The default value is always underlined. Example: ALL | DISTINCT |