

Support Vector Machines (SVMs) are a powerful set of supervised learning methods used for classification, regression, and outlier detection. This tutorial will guide you through implementing SVMs from scratch, focusing on classification. By the end, you’ll understand the theory behind SVMs and how to code them without relying on external libraries. This tutorial assumes you have a good grasp of Python and linear algebra.
1. Introduction to Support Vector Machines
What is a Support Vector Machine?
A Support Vector Machine (SVM) is a supervised machine learning algorithm that can be used for classification or regression challenges. It works by finding the hyperplane that best divides a dataset into classes. In a two-dimensional space, this hyperplane is a line dividing a plane into two parts where each class lies on either side.
Why Use SVM?
- Effective in high-dimensional spaces: Particularly useful when the number of dimensions exceeds the number of samples.
- Memory efficient: Uses a subset of training points in the decision function (called support vectors).
- Versatile: Different kernel functions can be specified for the decision function. Common kernels include linear, polynomial, RBF (Gaussian), and sigmoid.
2. Mathematical Foundation of SVM
Hyperplanes and Support Vectors
A hyperplane in an 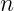 -dimensional space is a flat affine subspace of dimension
-dimensional space is a flat affine subspace of dimension  . For a 2D space, the hyperplane is a line. In SVM, we aim to find a hyperplane that maximizes the margin between the two classes. The points lying closest to the hyperplane are called support vectors.
. For a 2D space, the hyperplane is a line. In SVM, we aim to find a hyperplane that maximizes the margin between the two classes. The points lying closest to the hyperplane are called support vectors.
Margin
The margin is the distance between the hyperplane and the closest data points from either class. Maximizing the margin helps improve the model’s generalization ability.
Mathematical Formulation
Given a training dataset  where
where  and
and  , the decision function for a linear SVM is:
, the decision function for a linear SVM is:

The goal is to find  and
and 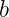 such that the margin is maximized. This can be formulated as a constrained optimization problem:
such that the margin is maximized. This can be formulated as a constrained optimization problem:
Minimize 
Subject to  for all
for all 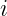 .
.
The Dual Problem
Using Lagrange multipliers, the above problem can be converted into its dual form, which is easier to solve:
Maximize:

Subject to:


where  are the Lagrange multipliers.
are the Lagrange multipliers.
Kernel Trick
The kernel trick allows SVM to create non-linear decision boundaries by transforming the input space into a higher-dimensional space where a linear separation is possible. Common kernels include:
- Linear Kernel:

- Polynomial Kernel:

- Radial Basis Function (RBF) Kernel:




3. Implementing SVM from Scratch
Data Preprocessing
Before we start coding the SVM, let’s preprocess the data. We’ll use the Iris dataset for simplicity.
import numpy as np
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
# Load the Iris dataset
iris = load_iris()
X = iris.data[:100, :2] # We will use only the first two features and two classes for simplicity
y = iris.target[:100]
# Convert the labels to {-1, 1}
y = np.where(y == 0, -1, 1)
# Split the data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Standardize the features
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)Code language: Python (python)Kernel Functions
Let’s implement some kernel functions:
def linear_kernel(x1, x2):
return np.dot(x1, x2)
def polynomial_kernel(x1, x2, degree=3, coef0=1):
return (np.dot(x1, x2) + coef0) ** degree
def rbf_kernel(x1, x2, gamma=0.1):
return np.exp(-gamma * np.linalg.norm(x1 - x2) ** 2)Code language: Python (python)Optimization Problem
The optimization problem involves finding the values of $latex \alpha) that maximize the dual problem. We will use the Sequential Minimal Optimization (SMO) algorithm to solve this.
Sequential Minimal Optimization (SMO)
SMO breaks the problem into smaller subproblems, which are then solved analytically. This approach significantly simplifies the optimization process.
class SVM:
def __init__(self, kernel=linear_kernel, C=1.0, tol=1e-3, max_passes=5):
self.kernel = kernel
self.C = C
self.tol = tol
self.max_passes = max_passes
def fit(self, X, y):
n_samples, n_features = X.shape
self.alpha = np.zeros(n_samples)
self.b = 0
self.X = X
self.y = y
passes = 0
while passes < self.max_passes:
num_changed_alphas = 0
for i in range(n_samples):
E_i = self._decision_function(X[i]) - y[i]
if (y[i] * E_i < -self.tol and self.alpha[i] < self.C) or (y[i] * E_i > self.tol and self.alpha[i] > 0):
j = np.random.randint(0, n_samples)
while j == i:
j = np.random.randint(0, n_samples)
E_j = self._decision_function(X[j]) - y[j]
alpha_i_old = self.alpha[i]
alpha_j_old = self.alpha[j]
if y[i] != y[j]:
L = max(0, self.alpha[j] - self.alpha[i])
H = min(self.C, self.C + self.alpha[j] - self.alpha[i])
else:
L = max(0, self.alpha[j] + self.alpha[i] - self.C)
H = min(self.C, self.alpha[j] + self.alpha[i])
if L == H:
continue
eta = 2 * self.kernel(X[i], X[j]) - self.kernel(X[i], X[i]) - self.kernel(X[j], X[j])
if eta >= 0:
continue
self.alpha[j] -= y[j] * (E_i - E_j) / eta
self.alpha[j] = np.clip(self.alpha[j], L, H)
if abs(self.alpha[j] - alpha_j_old) < 1e-5:
continue
self.alpha[i] += y[i] * y[j] * (alpha_j_old - self.alpha[j])
b1 = self.b - E_i - y[i] * (self.alpha[i] - alpha_i_old) * self.kernel(X[i], X[i]) - y[j] * (self.alpha[j] - alpha_j_old) * self.kernel(X[i], X[j])
b2 = self.b - E_j - y[i] * (self.alpha[i] - alpha_i_old) * self.kernel(X[i], X[j]) - y[j] * (self.alpha[j] - alpha_j_old) * self.kernel(X[j], X[j])
if 0 < self.alpha[i] < self.C:
self.b = b1
elif 0 < self.alpha[j] < self.C:
self.b = b2
else:
self.b = (b1 + b2) / 2
num_changed_alphas += 1
if num_changed_alphas == 0:
passes += 1
else:
passes = 0
def _decision_function(self, X):
return np.dot((self.alpha
* self.y), self.kernel(self.X, X)) + self.b
def predict(self, X):
return np.sign(self._decision_function(X))Code language: Python (python)Training and Testing the SVM
Now, let’s train our SVM model and test it on the test data.
# Initialize the SVM with a linear kernel
svm = SVM(kernel=linear_kernel, C=1.0)
# Train the SVM
svm.fit(X_train, y_train)
# Predict the test data
y_pred = svm.predict(X_test)
# Calculate the accuracy
accuracy = np.mean(y_pred == y_test)
print(f'Accuracy: {accuracy * 100:.2f}%')Code language: Python (python)6. Evaluation Metrics
While accuracy is a common metric, it’s important to consider other metrics, especially when dealing with imbalanced datasets.
Precision, Recall, and F1-Score
from sklearn.metrics import precision_score, recall_score, f1_score
precision = precision_score(y_test, y_pred)
recall = recall_score(y_test, y_pred)
f1 = f1_score(y_test, y_pred)
print(f'Precision: {precision:.2f}')
print(f'Recall: {recall:.2f}')
print(f'F1-Score: {f1:.2f}')Code language: Python (python)Confusion Matrix
A confusion matrix provides a detailed breakdown of prediction results.
from sklearn.metrics import confusion_matrix
conf_matrix = confusion_matrix(y_test, y_pred)
print('Confusion Matrix:')
print(conf_matrix)Code language: Python (python)7. Optimizations and Practical Tips
Handling Imbalanced Data
When dealing with imbalanced data, you can adjust the class weights.
class SVM:
def __init__(self, kernel=linear_kernel, C=1.0, tol=1e-3, max_passes=5, class_weight=None):
self.kernel = kernel
self.C = C
self.tol = tol
self.max_passes = max_passes
self.class_weight = class_weight
def fit(self, X, y):
n_samples, n_features = X.shape
self.alpha = np.zeros(n_samples)
self.b = 0
self.X = X
self.y = y
if self.class_weight:
weight = np.vectorize(self.class_weight.get)(y)
else:
weight = np.ones(n_samples)
passes = 0
while passes < self.max_passes:
num_changed_alphas = 0
for i in range(n_samples):
E_i = self._decision_function(X[i]) - y[i]
if (y[i] * E_i < -self.tol and self.alpha[i] < self.C * weight[i]) or (y[i] * E_i > self.tol and self.alpha[i] > 0):
j = np.random.randint(0, n_samples)
while j == i:
j = np.random.randint(0, n_samples)
E_j = self._decision_function(X[j]) - y[j]
alpha_i_old = self.alpha[i]
alpha_j_old = self.alpha[j]
if y[i] != y[j]:
L = max(0, self.alpha[j] - self.alpha[i])
H = min(self.C * weight[j], self.C * weight[j] + self.alpha[j] - self.alpha[i])
else:
L = max(0, self.alpha[j] + self.alpha[i] - self.C * weight[j])
H = min(self.C * weight[j], self.alpha[j] + self.alpha[i])
if L == H:
continue
eta = 2 * self.kernel(X[i], X[j]) - self.kernel(X[i], X[i]) - self.kernel(X[j], X[j])
if eta >= 0:
continue
self.alpha[j] -= y[j] * (E_i - E_j) / eta
self.alpha[j] = np.clip(self.alpha[j], L, H)
if abs(self.alpha[j] - alpha_j_old) < 1e-5:
continue
self.alpha[i] += y[i] * y[j] * (alpha_j_old - self.alpha[j])
b1 = self.b - E_i - y[i] * (self.alpha[i] - alpha_i_old) * self.kernel(X[i], X[i]) - y[j] * (self.alpha[j] - alpha_j_old) * self.kernel(X[i], X[j])
b2 = self.b - E_j - y[i] * (self.alpha[i] - alpha_i_old) * self.kernel(X[i], X[j]) - y[j] * (self.alpha[j] - alpha_j_old) * self.kernel(X[j], X[j])
if 0 < self.alpha[i] < self.C * weight[i]:
self.b = b1
elif 0 < self.alpha[j] < self.C * weight[j]:
self.b = b2
else:
self.b = (b1 + b2) / 2
num_changed_alphas += 1
if num_changed_alphas == 0:
passes += 1
else:
passes = 0Code language: Python (python)Feature Scaling
Feature scaling can significantly impact the performance of SVMs. Ensure that your data is standardized or normalized before training.
Parameter Tuning
Tuning parameters like  , kernel type, and kernel parameters is crucial for achieving optimal performance. Use grid search or randomized search to find the best parameters.
, kernel type, and kernel parameters is crucial for achieving optimal performance. Use grid search or randomized search to find the best parameters.
from sklearn.model_selection import GridSearchCV
from sklearn.svm import SVC
# Define the parameter grid
param_grid = {
'C': [0.1, 1, 10],
'kernel': ['linear', 'poly', 'rbf'],
'gamma': [0.001, 0.01, 0.1, 1],
'degree': [2, 3, 4]
}
# Initialize the SVM model
svc = SVC()
# Initialize the grid search
grid_search = GridSearchCV(svc, param_grid, cv=5, scoring='accuracy')
# Fit the grid search
grid_search.fit(X_train, y_train)
# Print the best parameters and score
print(f'Best Parameters: {grid_search.best_params_}')
print(f'Best Score: {grid_search.best_score_}')Code language: Python (python)8. Conclusion
In this tutorial, we’ve implemented a Support Vector Machine (SVM) from scratch. We’ve covered the mathematical foundations, implemented the SMO algorithm, and explored how to handle real-world challenges like imbalanced data and feature scaling. By understanding the inner workings of SVMs, you can better leverage their power and apply them effectively in various machine learning tasks.
Further Reading
- Pattern Recognition and Machine Learning by Christopher M. Bishop
- The Elements of Statistical Learning by Trevor Hastie, Robert Tibshirani, and Jerome Friedman
- Support Vector Machines: Concepts and Applications by Ingo Steinwart and Andreas Christmann
Practice Problems
- Implement SVM with a different kernel (e.g., polynomial or RBF) from scratch.
- Apply your SVM implementation to a different dataset (e.g., the digits dataset).
- Experiment with different values of
 and observe how it affects the decision boundary and performance.
and observe how it affects the decision boundary and performance.
By following this tutorial and experimenting further, you’ll gain a deep understanding of SVMs and be well-equipped to use them in your machine learning projects.